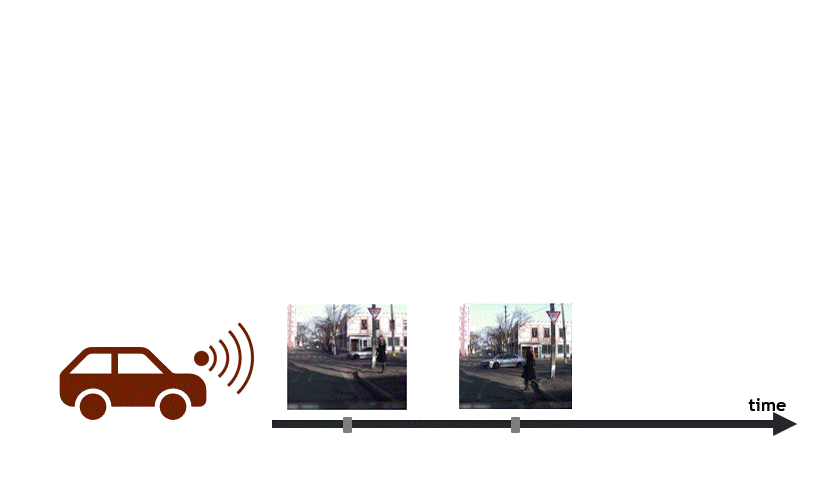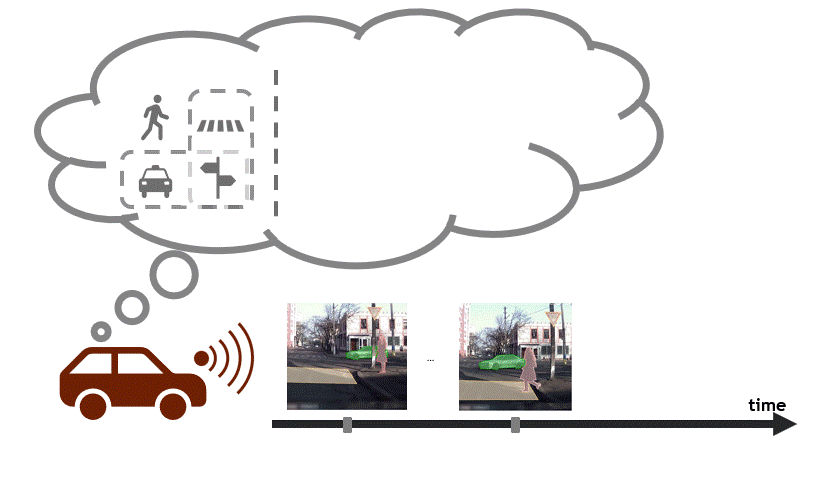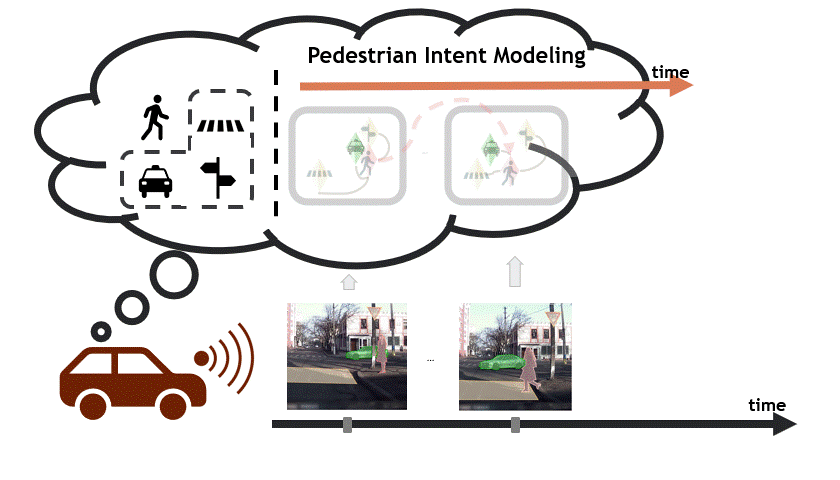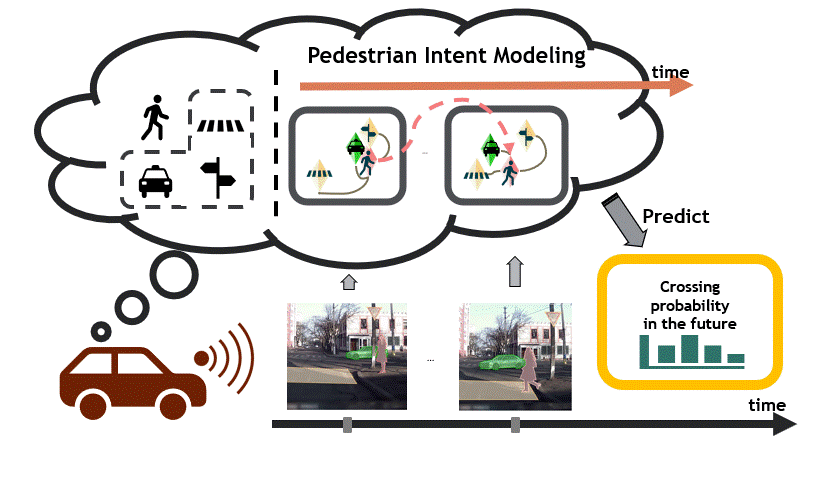
Reasoning over visual data is a desirable capability for robotics and vision-based applications. Such reasoning enables forecasting of the next events or actions in videos. In recent years, various models have been developed based on convolution operations for prediction or forecasting, but they lack the ability to reason over spatiotemporal data and infer the relationships of different objects in the scene. In this paper, we present a framework based on graph convolution to uncover the spatiotemporal relationships in the scene for reasoning about pedestrian intent. A scene graph is built on top of segmented object instances within and across video frames. Pedestrian intent, defined as the future action of crossing or not-crossing the street, is a very crucial piece of information for autonomous vehicles to navigate safely and more smoothly. We approach the problem of intent prediction from two different perspectives and anticipate the intention-to-cross within both pedestrian-centric and location-centric scenarios. In addition, we introduce a new dataset designed specifically for autonomous-driving scenarios in areas with dense pedestrian populations: the Stanford-TRI Intent Prediction (STIP) dataset. Our experiments on STIP and another benchmark dataset show that our graph modeling framework is able to predict the intention-to-cross of the pedestrians with an accuracy of 79.10% on STIP and 79.28% on Joint Attention for Autonomous Driving (JAAD) dataset up to one second earlier than when the actual crossing happens. These results outperform the baseline and previous work.