Dataset Details
Spatiotemporal Relationship Reasoning for Pedestrian Intent Prediction, IEEE RA-L & ICRA 2020 (
Arxiv)
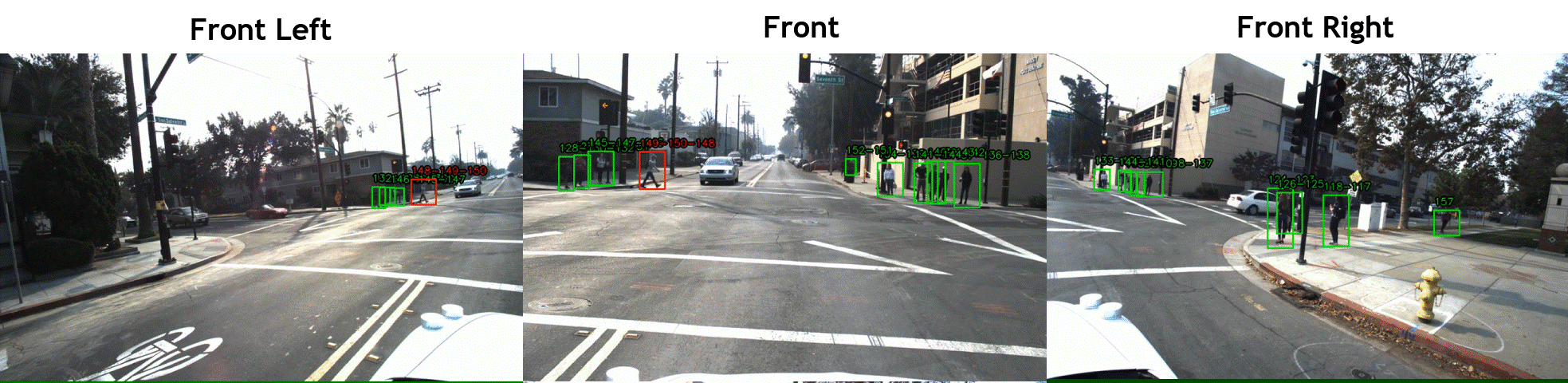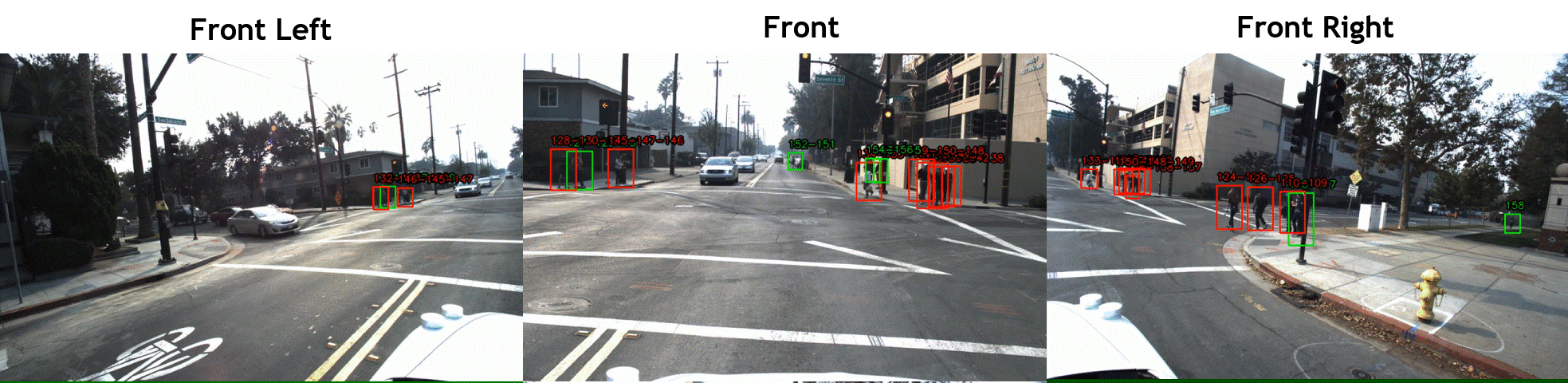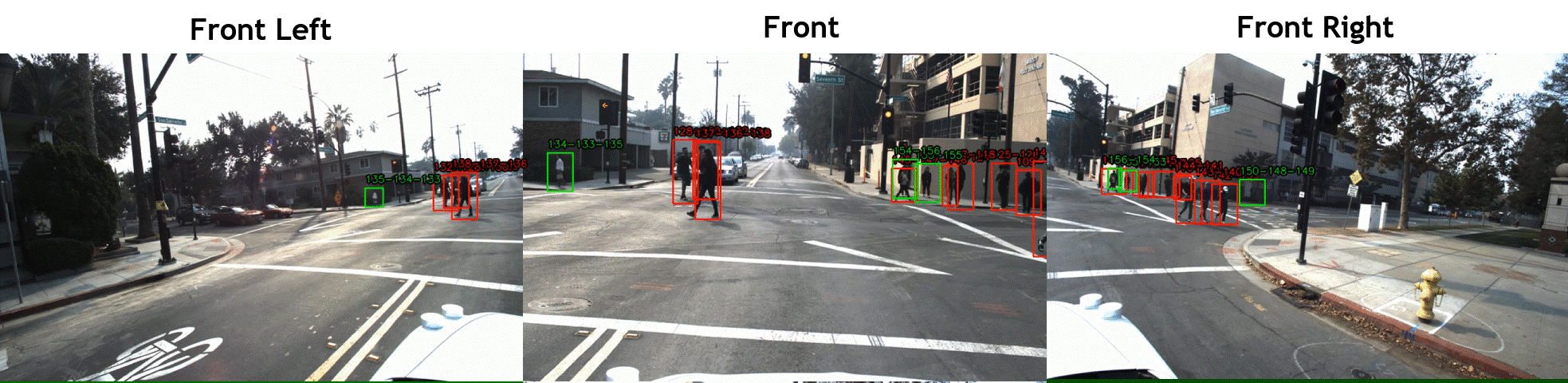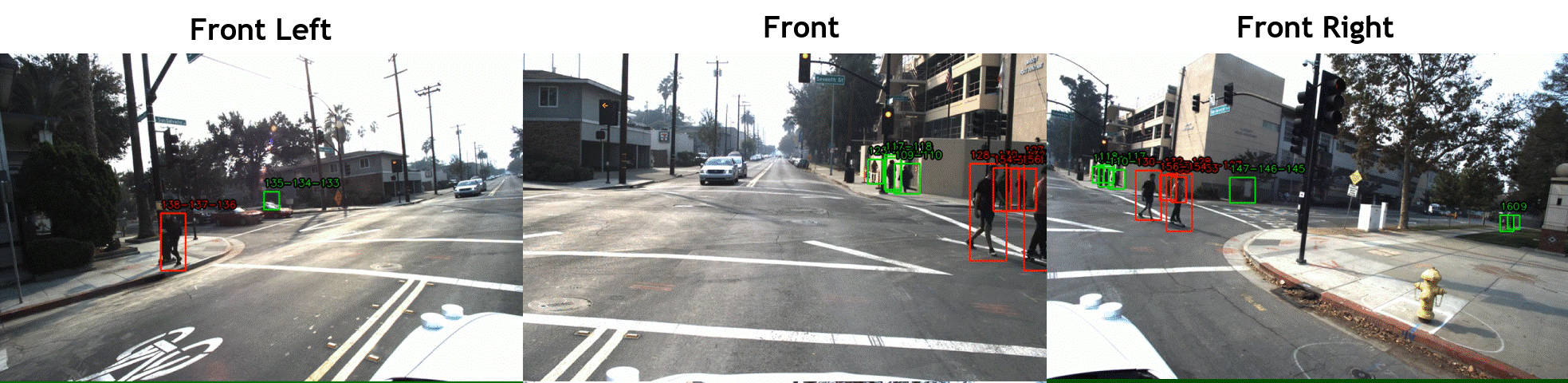
STIP includes over 900 hours of driving scene videos of front, right, and left cameras, while the vehicle was driving in dense areas of five cities in the United States. The videos were annotated at 2fps with pedestrian bounding boxes and labels of crossing/not-crossing the street, which are respectively shown with green/red boxes in the above videos. We used the
JRMOT (JackRabbot real-time Multi-Object Tracker) platform to track the pedestrian and interpolate the annotations for all 20 frame per second. See
https://github.com/StanfordVL/STIP/ for the details.




 nbsp;
nbsp;









